
北航 OO 面向对象 第四单元
转眼间,这趟面向对象程序设计的奇幻漂流也迎来了尾声。从第一单元初入茅庐的“表达式解析”,到第二单元扑朔迷离的“多线程电梯风云录”,再到第三单元严谨到令人发指的“JML”,直至本单元的图书馆怪谈“UML”,我历经了风雨的洗礼,变得更强、更稳、更有经验了。这篇博客是对第四单元和整个OO旅程的一次深度复盘与未来展望。
✨ 我的OO航海日志·珍藏版索引 ✨
一、本单元所实践的正向建模与开发
第四单元主要是设计UML图,并利用画好的UML图来实现一个图书馆管理系统。其中,我们应当采取正向建模的方式来完成作业。
**正向建模的核心奥义:“先有蓝图,再盖大楼”,在本单元的图书馆建设中体现得淋漓尽致:
解读指导书内容:
- 首先,要得把图书馆的规则理解透彻:书籍如何分类、学生如何借阅、预约、还书,信用分又是如何计算的,以及图书馆每日开闭馆时那套庄严的仪式(
open()和close())。 - 比如要先吃透指导书的内容,明确我们的需求是什么,之后才能准确的设计类和方法。这部分对应了在实际工程中理解用户需求的部分。
- 首先,要得把图书馆的规则理解透彻:书籍如何分类、学生如何借阅、预约、还书,信用分又是如何计算的,以及图书馆每日开闭馆时那套庄严的仪式(
绘制UML:
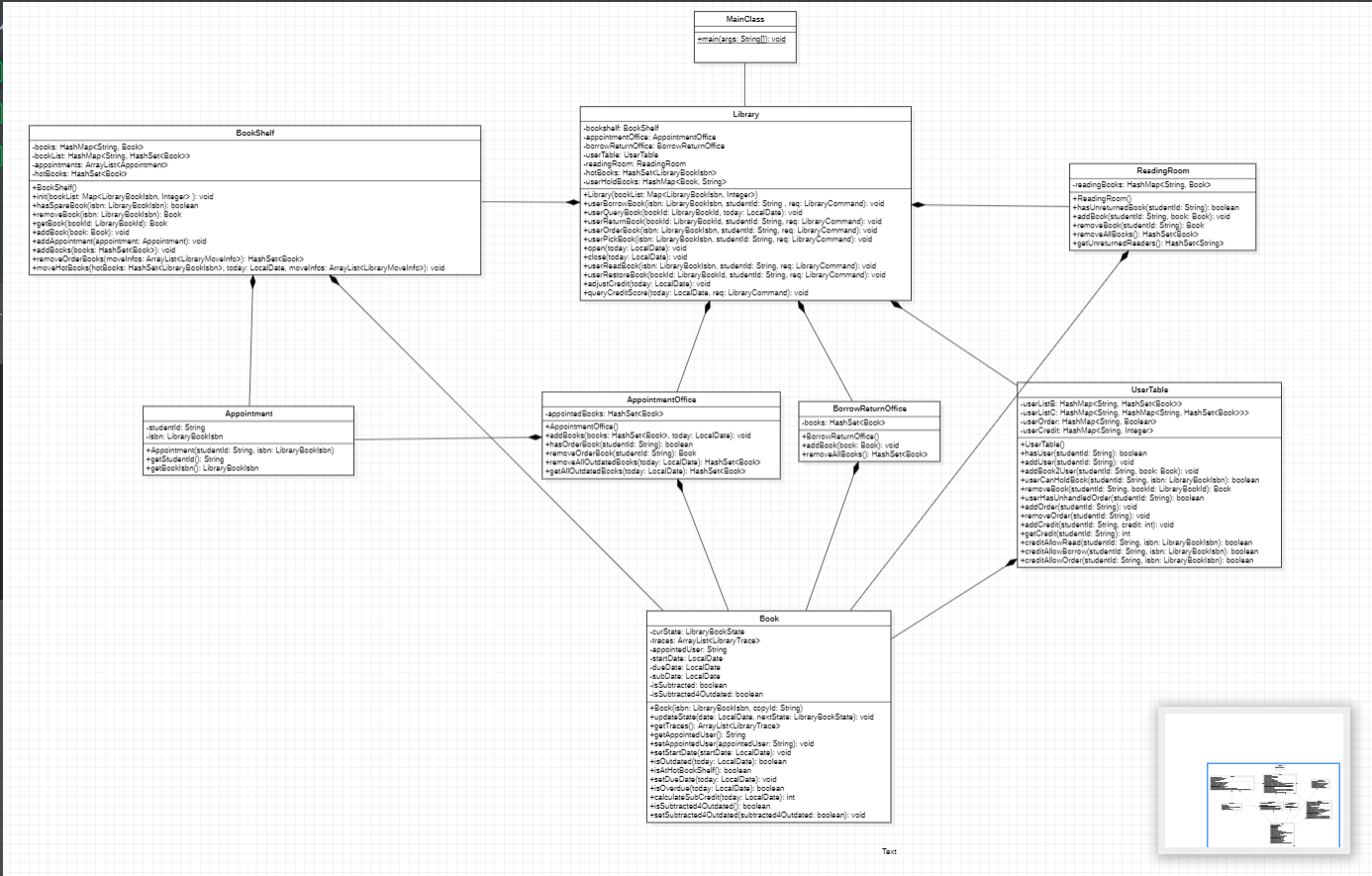
MainClass: 我的总指挥部,负责接收用户输入的指令,并精准分发给下级单位。Library: 系统的中枢神经!它像一位运筹帷幄的馆长,封装了图书馆几乎所有的核心业务逻辑,协调着手下各个“部门”高效运转。Book: 每一本书都封装了它的ISBN、独一无二的副本ID、当前位置、迁移记录、预约对象,还有各种日期戳以及是否“逾期”的标志位。BookShelf: 我的书库,不仅要按ID索引每一本实体书,还要按ISBN管理好各类书的可用副本集合,以及还要处理预约请求列表和馆内的人气王。AppointmentOffice: 预约管理中心,核心就是appointedBooks集合,专门预约好的书籍,还得处理好预约书的“保质期”问题。BorrowReturnOffice: 图书借还的“中转站”,一个简单的books集合,用于临时存放那些已经归还的书籍。UserTable: 学生档案管理处,通过好几个HashMap(userListB,userListC,userOrder,userCredit) 精细入微地管理着每位学生的借书情况(B类、C类书的限制可不一样)、预约状态和信用分。ReadingRoom: 阅览室,通过readingBooks(学生ID -> 书籍) 管理着室内的图书。Appointment: 一个二元组,记录着学生ID和他们预约的图书ISBN。
依据UML进行代码实现:
- 所有具体的指令处理逻辑,比如学生要借书 (
userBorrowBook)、还书 (userReturnBook),或是图书馆每日的开门 (open)、闭门 (close) 等,都是在我们的Library类中,通过操作我们预先定义好的这些模型对象(BookShelf的实例、UserTable的实例等)来完成的。 - 举个栗子,当一个借书请求输入,
Library会先问问BookShelf书库:“这本书还有存货吗?”,再查查UserTable档案:“这位同学借书资格如何?信用分够不够哇?”,一切妥当后,才会更新Book的状态,并在UserTable中为这位同学记录。
- 所有具体的指令处理逻辑,比如学生要借书 (
二、本单元作业的架构设计,对比分析最终的代码设计和UML模型设计之间的追踪关系
1. 我的图书馆系统架构蓝图
我的图书馆系统,核心当属 Library 类,它统一调度和管理着图书馆内部的各个功能组件。下面是我的架构分层解析:
**
MainClass:- 职责:从官方指定的
SCANNER那里接收各种输入。 - 行动:根据类型 (
LibraryOpenCmd,LibraryCloseCmd,LibraryReqCmd等),精准地调用对应执行方法。 - 定位:典型的控制器角色,负责将外部的原始输入,转化为对核心业务逻辑的优雅调用。
- 职责:从官方指定的
**
Library:- 几乎所有核心的业务操作方法,如
userBorrowBook,userReturnBook,userOrderBook,open,close,queryCreditScore等,都由它调用。 - 聚合众“部门”:
bookshelf: BookShelf: 掌管馆藏图书,提供图书的获取和归还接口。appointmentOffice: AppointmentOffice: 处理预约图书的暂存和“待领取”状态。borrowReturnOffice: BorrowReturnOffice: 作为图书归还后的“临时隔离区”。userTable: UserTable: 管理所有学生用户的信息、借阅历史、信用分等“机密档案”。readingRoom: ReadingRoom: 维护阅览室内的图书秩序。
- 开关门:
open()和close()方法不仅仅是开门关门那么简单,它们是图书馆运作状态转换的关键节点,负责执行每日的“清算”与“初始化”操作。 - 输出”: 通过课程组提供的
PRINTER工具,向外界播报处理结果。
- 几乎所有核心的业务操作方法,如
**功能组件层:
BookShelf: 内部通过books(HashMap<String, Book>) 按书籍的唯一ID(type-uid-copyId字符串)索引所有物理副本,方便O(1)查找;同时通过bookList(HashMap<String, HashSet<Book>>) 按ISBN字符串索引该ISBN下的所有可用副本集合,便于快速判断某种书是否有库存。还维护着一个appointments(ArrayList<Appointment>) 列表,用于初步收集预约请求,以及一个hotBooks(HashSet<Book>) 集合用于追踪热门书籍的原始ISBN。AppointmentOffice: 核心数据结构是appointedBooks(HashSet<Book>),专门管理那些已经成功预约并分配到具体学生的书籍,还要负责检查和处理这些预约书是否过期失效。BorrowReturnOffice: 结构相对简单,就是一个books(HashSet<Book>),作为归还书籍的临时存储空间。UserTable: 通过多个精心设计的HashMap(userListB,userListC,userOrder,userCredit),对每个学生的B类书(只能借一本)、C类书(同ISBN只能借一本)、是否有未处理的预约、以及信用分,都管理得井井有条。ReadingRoom: 维护一个readingBooks(HashMap<String, Book>),键是学生ID,值是该学生正在阅览室阅读的书籍,确保一人一次只能在阅览室阅读一本书。
**数据实体层 :
Book: 绝对的核心数据对象。内部存储书籍需要记录的核心数据。Appointment:记录着学生ID和他们想要预约的图书ISBN。
最后的UML类图如下:
2. 代码设计与我提供的UML模型之间的追踪关系
- Java类 & UML类:我的每一个Java源文件,比如
Library.java,Book.java,BookShelf.java等,在UML里都意义对应一个<UMLClassView>和一个<UMLClass>。 - 成员变量:每个类里的成员变量都与UML中的类的属性一一对应。包括可见性对应以及类型对应。比如
private final BookShelf bookshelf,在UML模型中就表现为Library类的一个属性。 - 类关系:每两个有关联关系的类在UML图中都有对应的compositon关联。
通过UML建模实践,我总结了编码经验:优秀的面向对象设计代码要尽可能结构清晰、职责分明,这样它天然就易于被UML这样的标准化建模语言所精确地描述和表达。
这充分说明了一个道理:UML模型,不仅仅可以在设计阶段充当指引我们编码的“蓝图”,也可以在代码完成后,作为一份精确、直观的“代码说明书”和“系统理解工具”。在我的第四单元图书馆系统中,代码和UML模型之间形成了一种非常理想的、相互印证、相互解释的良性循环。
三、大模型辅助架构设计
**如何引导AI在复杂场景中正确理解题目需求:
- “庖丁解牛”大法: 千万别指望AI一次性设计整个复杂系统。那样它只会给你一些泛泛而谈的空话。要把大问题拆解成一个个可管理的小模块、小功能点。然后针对每个小点,向AI精准地“发问”或要求它给出具体方案。
- 反面教材:“请帮我直接根据以上需求生成代码!”
- 正面引导:“假设你是图书管理员,我现在要设计图书馆的
UserTable类,它的核心职责是管理学生用户的信息。具体来说,我需要它记录每个学生当前借了哪些书,还要记录他们当前是否有未处理的预约请求,以及他们的信用分。请你构思一下,这个UserTable类应该包含哪些核心的成员变量和关键的公开方法呢?”
- 提供充足的“上下文信息” :
AI的智慧来源于它所“学习”到的数据。我们要想让它给出详细的架构设计,就得给它提供足够清晰、准确的背景资料和约束条件。- 提出新的需求:将现有的或者新的需求告诉AI,让AI充分学习新的规则。
- 反思回顾原有的背景: 我们需要让AI反思之前告诉他的信息,以及回顾AI之前生成的代码。
- “循循善诱”,实现迭代式进化”:
不要期望一次提问就能得到完美答案。架构设计本身就是一个反复打磨、逐步求精的过程。- 可以先从高层抽象入手,比如问AI:“一个图书馆系统,大致可以划分为哪些核心的功能模块或‘部门’呢?它们各自的主要职责是什么?” AI可能会给出类似
BookManagement,UserManagement,BorrowReturnProcess这样的初步划分。 - 然后,针对AI给出的每个模块(或者你自己构思的模块,比如
BookShelf,UserTable等),再深入进去,和AI一起“头脑风暴”其内部应该采用什么样的数据结构,需要暴求疵”,发现其中可能存在的逻辑漏洞、性能瓶颈或与业务需求不符之处,然后提出具体的追问,要求AI澄清、改进或提供替代方案。比如,对于AI初步设计的UserTable,你可以追问:“如果一个学生同时借阅了多本C类书(但它们的ISBN各不相同),我该如何设计数据结构才能高效地管理和查询他所借的所有C类书呢?”
- 可以先从高层抽象入手,比如问AI:“一个图书馆系统,大致可以划分为哪些核心的功能模块或‘部门’呢?它们各自的主要职责是什么?” AI可能会给出类似
四、我的架构设计思维进化史
回顾这四个单元的OO奇幻漂流,我的架构设计思维可以说是从“青铜”一路打怪升级到“王者”的进化史。在写代码和debug中不断积累经验,之后再写代码就具备一些架构头脑了,能够判断出哪些架构适合该需求。
- 第一单元:
- 我的架构:解析表达式主要依靠递归下降,将复杂的表达式递归地拆解为
Expr(表达式) ->Term(项) ->Factor(因子) 的清晰层次结构。这里的Factor,我设计成了一个接口,用它来统一管理不同种类的因此,包含了像Num,Var,Sin,Cos,Function,Dx等不同类型的因子,让它们都能在Factor的容器中存储。而在计算上,我更是贯彻了“化繁为简,统一指挥”的战略思想:所有不同形态的因子,最终都要“殊途同归”,被转换为结构统一的Poly(多项式) 对象,然后在Poly的层面进行标准化的运算(加法、乘法、乘方)。这种“解析过程”与“计算过程”彻底分离**两段式架构设计,自底向上调用toPoly()方法的优雅转换思路,为我后续的系统扩展和功能迭代,打下了坚如磐石的基础。
- 我的架构:解析表达式主要依靠递归下降,将复杂的表达式递归地拆解为
- 第二单元:
- 核心挑战:如何在多线程并发访问共享资源时管理好线程安全问题;以及如何设计出一套既高效又聪明的电梯调度策略,让乘客们最快速度到达目标楼层。
- 我的架构:我引入了生产者-消费者模式。输入线程扮演着“生产者”,源源不断地将乘客请求放入
RequestList这个“共享容器”。而我的Dispatcher则从容器中取出请求,并根据分派策略将其分配给各个电梯。电梯线程本身也是消费者,专注于处理分配到自己头上的那些请求。在调度策略上,我更是经历了从第一次作业的“简单粗暴”(直接指定电梯),到第二、三次作业的“精打细算”的调参算法(综合考虑电梯与请求者之间的距离、电梯当前“度量”、电梯的运行速度、乘客的“VIP等级”即优先级等多种因素,为每个电梯打出一个综合得分,优胜劣汰),可谓是不断追求卓越。电梯内部的运行逻辑,则遵循了高效的LOOK算法,并通过一个专门的ElevatorStrategy类进行了优雅的封装。
- 第三单元:
- 核心挑战:如何理解JML,并精确无误地实现一个复杂的社交网络系统,并且还要时刻避免一不小心就TLE的悲剧。
- 我的架构:架构设计主要是JML决定的。其中将社交网络抽象成一个图模型:
Person对象是图中的“节点”,而人与人之间的Relation则是图中的“边”。整个单元的核心,就是一丝不苟地遵循JML规格文档,去精确实现每一个接口方法。同时还要估计搞复杂度方法的优化,比如对于那个看似简单的query_triple_sum,我通过在添加/删除关系时动态维护一个tripleSum计数器变量,硬生生地将查询复杂度从O(N^3)优化到了惊人的O(1)!类似的,query_couple_sum也被我优化到了O(N)的遍历复杂度;而query_value_sum则采用了更复杂的动态维护策略,以均摊复杂度。甚至在处理delete_article时,我还深入比较了LinkedList与ArrayList在删除操作上的性能差异,并思考了使用自定义双向链表配合HashMap来实现理论最优O(1)删除的“终极方案”。
- 第四单元:
- 核心挑战:挑战新的项目设计逻辑:先画出UML图,再根据架构图实现代码。
- 我的架构:上文已经介绍的非常详尽了,这里就不过多赘述了。
我在OO宇宙中的进化轨迹总结:
在这一路上,我对面向对象的基石——抽象、封装、继承(虽然在本课程中,我更多地是通过接口来实现类似继承的多态效果,但其精髓是相通的!)、多态的理解,以及对诸如生产者-消费者、外观模式、策略模式、状态模式等常用设计模式的认知和应用能力,都在一次又一次的“被虐”与“反杀”的实战挑战中,不断深化、不断成熟,最终化为我代码功力的一部分。
五、我的测试思维进化论
- 我在四次作业中的测试都是通过评测机测试 + 手搓极端样例的方式实现的。
- 从第一次作业开始,我就使用评测机来进行代码测试。从手搓数据生成器,到书写多线程测试主程序,自己搓评测机的过程锻炼了我的代码能力,也让我多了解了程序评测机的基本逻辑和功能实现。
- 手搓极端样例的方式可以弥补评测机随机生成数据的不足和缺陷。一般来说评测机生成的数据都不会非常极端,比如连续10000条输入都是相同的。这也就说明评测机侧重的是测试的广度,而非深度。但是强测的数据点往往会侧重于考察某一个具体的漏洞,比如时间复杂度过高而引起的TLE等,这些极端数据评测机几乎不可能生成,因此必须手搓。手搓的方式就是识别程序中薄弱的地方和潜在的漏洞,然后自己构造一些卡时间的样例或者很复杂的情景,来测试自己程序的健康性。
六、我的OO课程通关感悟
当我敲下这篇总结博客的最后一个字符,也意味着我这趟面向对象程序设计之旅即将画上一个虽不舍但却圆满的句号。回首这四个单元的点点滴滴,OO带给我的,早已远远超出了Java语言本身和那几个具体的题目。这更像是一场思维模式的深度洗礼,一场解决复杂问题能力的系统重塑,一场让我窥见“代码之外星辰大海”的奇妙探险。
最后,也是最重要的,我要由衷地感谢课程组的每一位老师和助教们!是你们的精心策划、巧妙设计和辛勤付出,才为我们呈现了这门如此富有挑战性与启发性的面向对象程序设计课程。虽然在这几个月里,我的生活常常因为赶OO的ddl,但是这门课所带给我的收获必将化为我未来在计算机科学的星辰大海中继续探索和遨游的坚实基础与不竭动力!
OO的探险奇旅,至此已悄然驶向终点站。但,面向对象的思考方式与探索精神,永不落幕!
Cheers to OO! 🍻 And may the Source (Code) be with you! 😉



![北航2026软件工程作业 [I.1] 个人作业:阅读和提问](https://cdn.jsdelivr.net/gh/Justlovesmile/CDN2/post/cover4.jpg)

