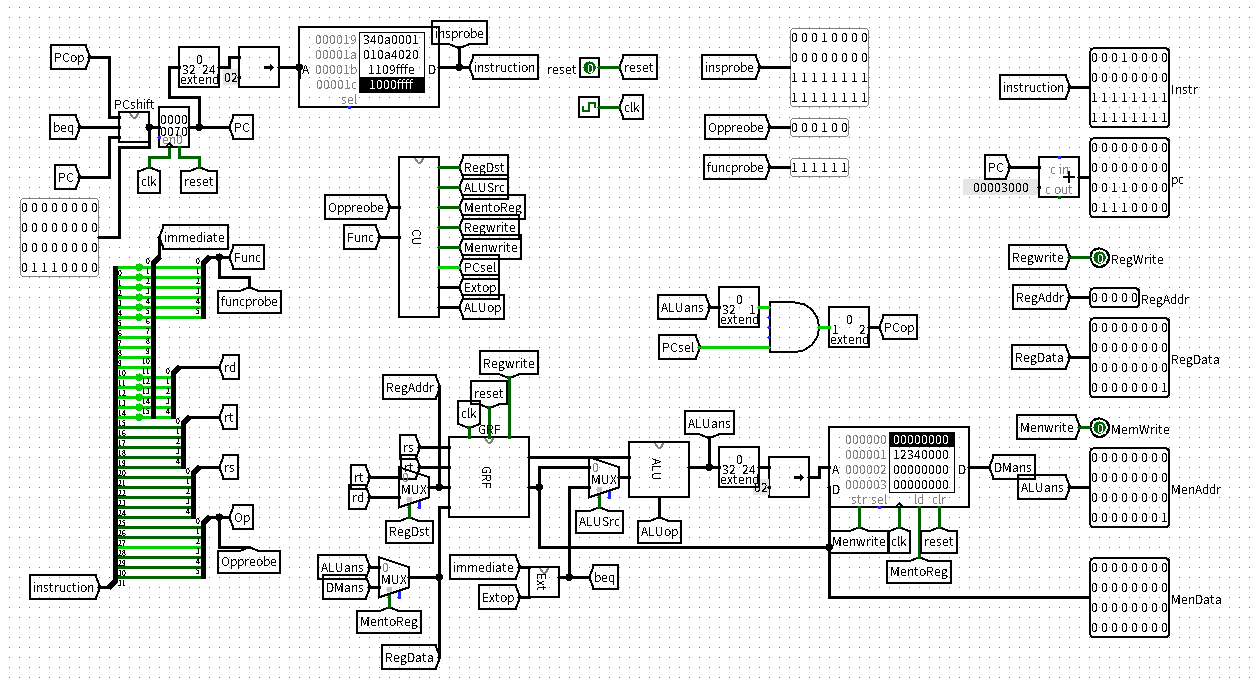
CPU_P4_design
1. 分析指令集
- 经过分类,指令共包含R型指令和I型指令
- 列出其对应的32位机器码,寻找共性差异
R型指令:
| Type | Op | Rs | Rt | Rd | Shamt | Func | 解释 |
|---|---|---|---|---|---|---|---|
| add | 000000 | (5) | (5) | (5) | 00000 | 100000 | 相加(rs+rt->rd) |
| sub | 000000 | (5) | (5) | (5) | 00000 | 100010 | 相减(rs-rt->rd) |
I型指令:
| Type | Op | Rs | Rt | Immediate | 解释 |
|---|---|---|---|---|---|
| ori | 001101 | (5) | (5) | (16) | 或运算(rs|immediate->rt) |
| lui | 001111 | 00000 | (5) | (16) | 立即数加载至高16位({immediate||{16{1’b0}}}->rt) |
| Type | Op | Rs | Rt | Offset | 解释 |
|---|---|---|---|---|---|
| lw | 100011 | (5) | (5) | (16) | 加载字(rs+offset在memory中data->rt) |
| sw | 101011 | (5) | (5) | (16) | 保存字(rt->rs+offset在memory中的data) |
| beq | 000100 | (5) | (5) | (16) | rs与rt相等则PC偏移offset*4 |
J型指令
| type | Op | instr_index | 解释 |
|---|---|---|---|
| jal | 000011 | (26) | 跳转至index并且PC+4 -> $ra |
| type | Op | rs | 0 | 0 | func | 解释 |
|---|---|---|---|---|---|---|
| jr | 000000 | (5) | {10{1’b0}} | {5{1’b0}} | 001000 | 跳转至$rs中的地址 |
2. PC设计
端口设计:
| 方向 | name | 位宽 |
|---|---|---|
| input | PCop | [3:0] |
| input | beq | [31:0] |
| input | jal | [31:0] |
| input | jr | [31:0] |
| input | reset | 1 |
| input | clk | 1 |
| output | PC | [31:0] |
转移设计:
| PCop | 解释 |
|---|---|
| 0000 | PC <= PC + 4 |
| 0001 | PC <= PC + 4 + beq |
| 0010 | PC <= jal |
| 0011 | PC <= jr |
3. IM设计
端口设计:
| 方向 | name | 位宽 |
|---|---|---|
| input | PC | [31:0] |
| output | instruction | [31:0] |
转移设计:
| 解释 |
|---|
| instruction <= instruction_memory[PC] |
4. 设计splitter
端口设计:
| 方向 | name | 位宽 |
|---|---|---|
| input | instruction | [31:0] |
| output | Op | [5:0] |
| output | Func | [5:0] |
| output | rs | [4:0] |
| output | rt | [4:0] |
| output | rd | [4:0] |
| output | immediate | [15:0] |
| output | jal | [25:0] |
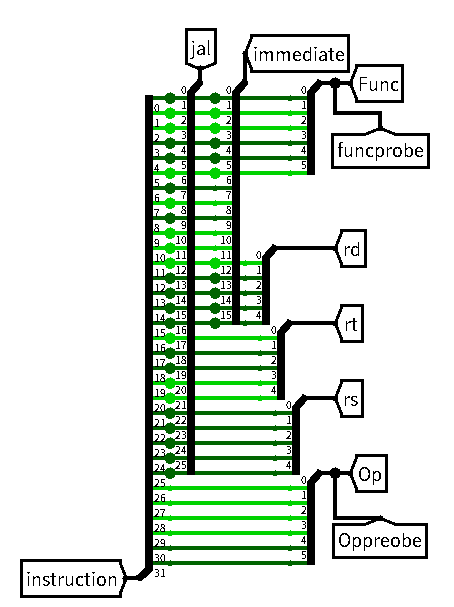
5. 设计ALU
ALU端口设计:
| type | name | 位宽 |
|---|---|---|
| input | num1 | [31:0] |
| input | num2 | [31:0] |
| input | ALUop | [7:0] |
| output | ans | [31:0] |
ALUop解释:
| ALUop | 解释 |
|---|---|
| 10001 | 加法 |
| 10010 | 减法 |
| 10011 | 与运算 |
| 10100 | 或运算 |
| 10101 | 异或运算 |
| 10110 | 相等 |
| 10111 | 大于 |
| 11000 | 小于 |
6. CU
端口设计:
| type | name | 位宽 | 解释 |
|---|---|---|---|
| input | Op | [5:0] | 机器码高6位 |
| input | Func | [5:0] | 机器码低6位 |
| output | RegDst | [1:0] | GRF被写入寄存器是rt还是rd。0是rt,1是rd,10是$ra |
| output | ALUSrc | [1:0] | ALU第二个运算值是rt还是立即数。0是rt,1是立即数 |
| output | memtoReg | [1:0] | GRF写入值是ALUans还是DMans。0是ALUans,1是DMans,10是PC + 4 |
| output | Regwrite | 1 | 是否写入GRF |
| output | Memwrite | 1 | 是否写入RAM |
| output | PCsel | [3:0] | 当前指令是否是beq\jal\jr |
| output | Extop | [7:0] | 扩展操作类型类型,详见Extender |
| output | ALUop | [7:0] | ALU运算类型,详见ALU |
| output | instr_type | [7:0] | 指令类型 |
- 内部电路采用最小项表达式判断法,先判断Op,再判断Func
每种指令所需控制信号:
| RegDst | ALUSrc | memtoReg | Regwrite | Memwrite | PCsel | Extop | ALUop | |
|---|---|---|---|---|---|---|---|---|
| add | 01 | 00 | 00 | 1 | 0 | 0000 | ADD | |
| sub | 01 | 00 | 00 | 1 | 0 | 0000 | SUB | |
| ori | 00 | 01 | 00 | 1 | 0 | 0000 | 0000 | OR |
| lui | 00 | 01 | 00 | 1 | 0 | 0000 | 0010 | ADD |
| lw | 00 | 01 | 01 | 1 | 0 | 0000 | 0001 | ADD |
| sw | 01 | 0 | 1 | 0000 | 0001 | ADD | ||
| beq | 00 | 0 | 0 | 0001 | 0011 | EQUAL | ||
| jal | 10 | 10 | 1 | 0 | 0010 | 0100 | ||
| jr | 00 | 0 | 0 | 0011 | ADD |
7. Extender
端口类型:
| type | name | 位宽 |
|---|---|---|
| input | num | [15:0] |
| input | jal | [25:0] |
| input | Extop | [3:0] |
| input | PC | [31:0] |
| output | ans | [31:0] |
Extop类型解释:
| Extop | 解释 |
|---|---|
| 0000 | zero扩展 |
| 0001 | sign扩展 |
| 0010 | 低16位移至高16位,补0 |
| 0011 | sign扩展,左移2位,补0 |
| 0100 | PC高4位,jal补2位0 |
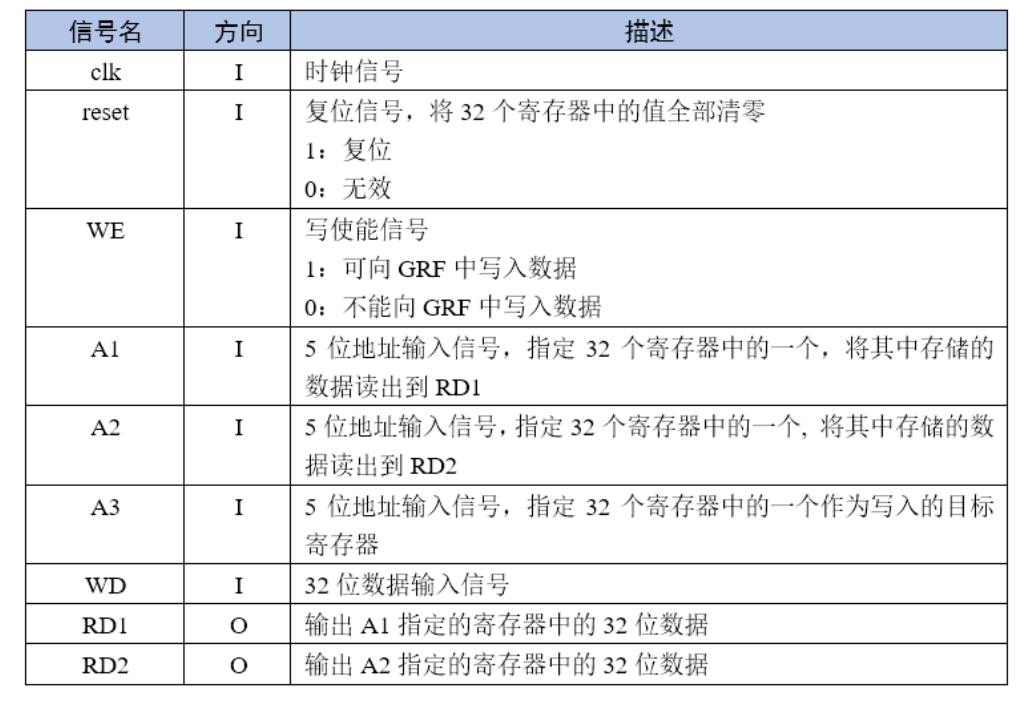
8.GRF
9. DM
端口设计:
| 方向 | name | 位宽 |
|---|---|---|
| input | addr | [31:0] |
| input | WD | [31:0] |
| input | clk | 1 |
| input | reset | 1 |
| input | WE | 1 |
| output | data | [31:0] |
10. 测试方案
- 通过机器码来检验正确性。根据输出来比对MARS中操作行为。
- 通过评测机来检验正确性。
11. 思考题
addr信号是ALU计算得到的,在lw或sw指令中,ALU将一个寄存器中的值和立即数经扩展移位之后的结果相加,得到的运算结果为address,作为addr端传入到DM中去访存数据。addr位数是[11:2]是因为addr的单位是字节,但是DM中memory数组的位宽是[31:0],也就是一字。一字等于四字节。取addr的[11:2]位相当于将addr右移两位,即整除4,其代表的含义是该addr所在的字地址。通过该字地址,我们可以访存DM中addr的数据。
第一种是每种指令所对应的控制信息,代码示例如下:
1 | reg [31:0] instr; |
好处:条理清晰,每种指令所对应的输出端口一目了然,结构层级明显,不容易出错,debug难度较低,便于统计。
坏处:每一条指令均需要罗列全部的输出端口,重复性操作较多,添加指令较为麻烦。
第二种是每种控制信息所需要的指令,代码示例如下:
1 | reg [31:0] instr; |
好处:操作简单,新增指令只需要新增对应输出端口的判断条件即可,可维护性较强。
缺点:可读性差,debug难度较高,无法直观显示指令与输出之间的关系。
同步复位是指,所有复位操作均在时钟上升沿进行。即reset在时钟周期中有效不会立即生效,得保持到clk上升沿才能复位。clk优先级高于reset。 异步复位是指,reset有效时立即复位,因此不用等到clk上升沿即可复位。reset优先级高于clk。
add或者addi首先检查两个操作数是否是合法的word,如果不是,会抛出UndefinedResult()异常。之后尝试相加并判断相加之后是否有符号溢出,如果符号溢出则会抛出SignalException()异常。如果不溢出则赋值给相应寄存器。addu或者addiu也会首先检查两个操作数是否是合法的word,如果不是则同样抛出UndefinedResult()异常。不一样的地方在于,相加之后取结果的[31:0]位直接复制给对应寄存器。这是因为对于无符号数,没有符号位,每一位的位权都是正的,因此直接相加即可,取低32位为运算结果。但有符号数的最高位是符号位,如果因为相加进位导致符号位的改变,则会改变运算结果的符号,因此需要判断是否有符号溢出。如果不考虑符号溢出,则无需关注相加是否导致符号位改变,只需要相加取低32位即可,默认程序员会维护加法运算。因此在不考虑溢出的情况下,有符号加法和无符号加法的操作方式都是一样的,可以认为是等价。
附一张Logisim的CPU框架方便理解