
CPU_P6_design
1. 分析指令集
- 经过分类,指令共包含R型指令和I型指令
- 列出其对应的32位机器码,寻找共性差异
R型指令:
| Type | Op | Rs | Rt | Rd | Shamt | Func | 解释 |
|---|---|---|---|---|---|---|---|
| add | 000000 | (5) | (5) | (5) | 00000 | 100000 | 相加(rs+rt->rd) |
| sub | 000000 | (5) | (5) | (5) | 00000 | 100010 | 相减(rs-rt->rd) |
| and | 000000 | (5) | (5) | (5) | 00000 | 100100 | rs & rt -> rd |
| or | 000000 | (5) | (5) | (5) | 00000 | 100101 | rs | rt -> rd |
| slt | 000000 | (5) | (5) | (5) | 00000 | 101010 | rs < rt ? 1 : 0(signed) |
| sltu | 000000 | (5) | (5) | (5) | 00000 | 101011 | rs < rt ? 1 : 0(unsigned) |
| mfhi | 000000 | 00000 | 00000 | (5) | 00000 | 010000 | HI ->rd |
| mflo | 000000 | 00000 | 00000 | (5) | 00000 | 010010 | LO -> rd |
| Type | Op | Rs | Rt | 0 | Func | 解释 |
|---|---|---|---|---|---|---|
| mult | 000000 | (5) | (5) | 0000000000 | 011000 | rs * rt -> (HI, LO)(signed) |
| multu | 000000 | (5) | (5) | 0000000000 | 011001 | rs * rt -> (HI, LO)(unsigned) |
| div | 000000 | (5) | (5) | 0000000000 | 011010 | rs / rt -> (HI, LO)(signed) |
| divu | 000000 | (5) | (5) | 0000000000 | 011011 | rs / rt -> (HI, LO)(unsigned) |
| Type | Op | Rs | 0 | Func | 解释 |
|---|---|---|---|---|---|
| mthi | 000000 | (5) | 000000000000000 | 010001 | rs -> HI |
| mtlo | 000000 | (5) | 000000000000000 | 010011 | rs -> LO |
I型指令:
| Type | Op | Rs | Rt | Immediate | 解释 |
|---|---|---|---|---|---|
| ori | 001101 | (5) | (5) | (16) | 或运算(rs|immediate->rt) |
| lui | 001111 | 00000 | (5) | (16) | 立即数加载至高16位({immediate||{16{1’b0}}}->rt) |
| addi | 001000 | (5) | (5) | (16) | rs + immediate -> rt |
| andi | 001100 | (5) | (5) | (16) | rs & immediate -> rt |
| Type | Op | Rs | Rt | Offset | 解释 |
|---|---|---|---|---|---|
| lw | 100011 | (5) | (5) | (16) | 加载字(rs+offset在memory中data->rt) |
| sw | 101011 | (5) | (5) | (16) | 保存字(rt->rs+offset在memory中的data) |
| beq | 000100 | (5) | (5) | (16) | rs与rt相等则PC偏移offset*4 |
| lb | 100000 | (5) | (5) | (16) | mem中rs +offset对应字节符号拓展 -> rt |
| lh | 100001 | (5) | (5) | (16) | mem中rs +offset对应半字符号拓展 -> rt |
| sb | 101000 | (5) | (5) | (16) | rt[7:0] -> mem(offset + rs) |
| sh | 101001 | (5) | (5) | (16) | rt[15:0] -> mem(offset + rs) |
| bne | 000101 | (5) | (5) | (16) | 不相等则跳转 |
J型指令
| type | Op | instr_index | 解释 |
|---|---|---|---|
| jal | 000011 | (26) | 跳转至index并且PC+4 -> $ra |
| type | Op | rs | 0 | 0 | func | 解释 |
|---|---|---|---|---|---|---|
| jr | 000000 | (5) | {10{1’b0}} | {5{1’b0}} | 001000 | 跳转至$rs中的地址 |
2. 阶段分析
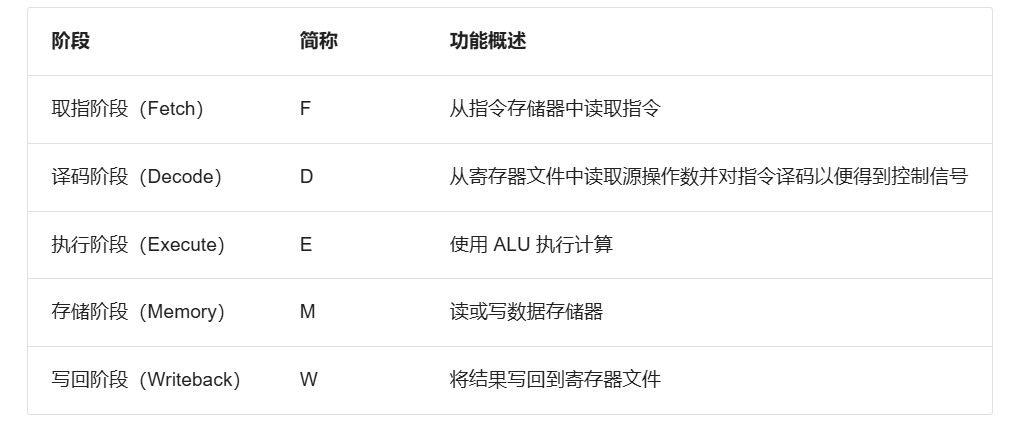
F阶段PC值已经确定,进行的是根据PC访存相应的Instruction操作。此时指令已经确定好了
D阶段是将instruction转换成对应的操作数、产生控制信号。
E阶段是将操作数转换成计算结果。
M阶段是方寸数据内存。
W阶段是写入GRF。
3.命名规则
采用首字母大写命名法,每个单词首字母大写。
4. PC设计
端口设计:
| 方向 | name | 位宽 |
|---|---|---|
| input | PcOp | [3:0] |
| input | BeqPc | [31:0] |
| input | JalPc | [31:0] |
| input | JrPc | [31:0] |
| input | reset | 1 |
| input | clk | 1 |
| output | Pc_F | [31:0] |
| input | BnePc | [31:0] |
转移设计:
| PcOp | 解释 |
|---|---|
| 0000 | Pc_F <= Pc_F + 4 |
| 0001 | Pc_F <= BeqPc |
| 0010 | Pc_F <= JalPc |
| 0011 | Pc_F <= JrPc |
| 0100 | Pc_F <= BnePc |
5. CU控制信号分析
端口设计:
| type | name | 位宽 | 解释 |
|---|---|---|---|
| input | Op | [5:0] | 机器码高6位 |
| input | Func | [5:0] | 机器码低6位 |
| output | RegDst | [1:0] | GRF被写入寄存器是rt还是rd。0是rt,1是rd,10是$ra |
| output | AluSrc | [1:0] | ALU第二个运算值是rt还是立即数。0是rt,1是立即数 |
| output | MemToReg | [1:0] | GRF写入值是ALUans还是DMans。0是ALUans,1是DMans,10是PC + 4 |
| output | RegWrite | 1 | 是否写入GRF |
| output | MemWrite | 1 | 是否写入RAM |
| output | PcSel | [3:0] | 当前指令是否是beq\jal\jr |
| output | ExtOp | [7:0] | 扩展操作类型类型,详见Extender |
| output | AluOp | [7:0] | ALU运算类型,详见ALU |
| output | InstrType | [7:0] | 指令类型 |
| output | TNew_D | [3:0] | 从D级开始,经过多少周期该指令产生运算结果 |
| output | TUse1_D,TUse2_D | [3:0] | 从D级开始,经过多少周期要用到运算结果 |
| output | Multiply_D | 1 | 是否进行乘法操作 |
| output | Divide_D | 1 | 是否进行除法操作 |
- 内部电路采用最小项表达式判断法,先判断Op,再判断Func
每种指令所需控制信号:
| RegDst | AluSrc | MemToReg | RegWrite | MemWrite | PcSel | ExtOp | AluOp | TNew | TUse1 | TUse2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| add | 01 | 00 | 00 | 1 | 0 | 0000 | ADD | 2 | 1 | 1 | |
| sub | 01 | 00 | 00 | 1 | 0 | 0000 | SUB | 2 | 1 | 1 | |
| ori | 00 | 01 | 00 | 1 | 0 | 0000 | 0000 | OR | 2 | 1 | 10 |
| lui | 00 | 01 | 00 | 1 | 0 | 0000 | 0010 | ADD | 2 | 10 | 10 |
| lw | 00 | 01 | 01 | 1 | 0 | 0000 | 0001 | ADD | 3 | 1 | 10 |
| sw | 11 | 01 | 0 | 1 | 0000 | 0001 | ADD | 0 | 1 | 2 | |
| beq | 11 | 00 | 0 | 0 | 0001 | 0011 | EQUAL | 0 | 0 | 0 | |
| jal | 10 | 10 | 1 | 0 | 0010 | 0100 | 0 | 10 | 10 | ||
| jr | 11 | 00 | 0 | 0 | 0011 | ADD | 0 | 0 | 10 |
6. 流水线寄存器存储信息分析
F级:
| name | 位宽 |
|---|---|
| Pc_F | [31:0] |
| Instruction_F | [31:0] |
D级:
| name | 位宽 |
|---|---|
| Pc_D | [31:0] |
| RD1_D | [31:0] |
| RD2_D | [31:0] |
| WR_D | [4:0] |
| ExtAns_D | [31:0] |
| MemToReg_D | [1:0] |
| RegWrite_D | 1 |
| AluSrc_D | [1:0] |
| MemWrite_D | 1 |
| AluOp_D | [7:0] |
| InstrType_D | [7:0] |
| TNew_D | [7:0] |
| Addr1_D | [4:0] |
| Addr2_D | [4:0] |
E级:
| name | 位宽 |
|---|---|
| Pc_E | [31:0] |
| AluAns_E | [31:0] |
| WR_E | [4:0] |
| RD2_E | [31:0] |
| MemToReg_E | [1:0] |
| RegWrite_E | 1 |
| MemWrite_E | 1 |
| InstrType_E | [7:0] |
| TNew_E | [7:0] |
| Addr2_E | [4:0] |
M级:
| name | 位宽 |
|---|---|
| Pc_M | [31:0] |
| AluAns_M | [31:0] |
| WR_M | [4:0] |
| DmAns_M | [31:0] |
| MemToReg_M | 1 |
| RegWrite_M | 1 |
| InstrType_M | [7:0] |
| TNew_M | [7:0] |
W级:
| name | 位宽 |
|---|---|
| Pc_W | [31:0] |
| AluAns_W | [31:0] |
| WR_W | [4:0] |
| DmAns_W | [31:0] |
| MemToReg_W | [1:0] |
| RegWrite_W | 1 |
| InstrType_W | [7:0] |
| TNew_W | [7:0] |
7. 流水线转发数据
E级:
| instruction | Data_E |
|---|---|
| add | 0 |
| sub | 0 |
| ori | 0 |
| lui | 0 |
| beq | 0 |
| jal | Pc_E + 8 |
| jr | 0 |
| lw | 0 |
| sw | 0 |
M级:
| instruction | Data_M |
|---|---|
| add | AluAns_M |
| sub | AluAns_M |
| ori | AluAns_M |
| lui | AluAns_M |
| beq | 0 |
| jal | Pc_M + 8 |
| jr | 0 |
| lw | 0 |
| sw | 0 |
W级:
| instruction | Data_W |
|---|---|
| add | AluAns_W |
| sub | AluAns_W |
| ori | AluAns_W |
| lui | AluAns_W |
| beq | 0 |
| jal | Pc_W + 8 |
| jr | 0 |
| lw | DmAns_W |
| sw | 0 |
8. 测试方案
针对每一条新添加的指令都进行测试,确保有符号、无符号的正确性,以及周期数的正确。
1 | ori $t0 12 |
9. 思考题汇总
- 因为乘除法所需的时钟周期不同,分别是5和10,而一般的ALU操作的时钟周期都是1。如果将乘除功能整合进ALU,会阻塞其他指令的正常进行,使得总周期数变长,指令效率变低。而独立出来则可以与ALU分别计算,增加指令执行效率。需要额外增加HI、LO是因为乘除法的计算结果需要保留,直到reset或者被重新计算新的乘除结果。如果不加,那就会被其他的计算覆盖掉,导致mfhi、mflo指令来不及生效。
- 从80486时代开始,CPU有了专用的乘法器、移位器运算单元,这些单元可以高效处理乘除法。乘法器通常把乘法运算拆分成多个步骤,例如分解成部分积生成、部分积相加、最终结果输出等几个阶段。CPU也有专用的除法器用来实现除法操作。通常采用特定的算法(Radix-2算法)来实现。
- 可以把乘法、除法运算当作Moore型有限状态机来处理,start和busy信号是输出。当E级的start或busy信号置1同时D级是乘除法相关的指令时,需要阻塞。
- 好处有很多:sw、sh、sb三种store型指令都可以用这个byteen信号来调控写入的字节段,不用为了每种指令单独设计写入信号,起到了统一的作用。同时byteen的每一个1都对应了一个专属的字节,这样可以清晰的写入,不怕混淆。
- 并不是一字节,而是一字,即四字节。当每次只写入或读出一字节时,按字节读写的效率会高于按字读写。
- 我对指令采取了归类的方式,先将具体的小指令提取共性归为同一类型的指令,再根据该类型的指令的特点来驱动输出信号。例如mult和multu指令分为乘法类,用来驱动Multiply_D信号,div和divu指令分为除法类等。这种手段在译码的时候能够降低指令的复杂度,减少操作次数,更清楚的分类分层。同时在阻塞和转发的时候也根据每一级的指令类型来决定转发的数据,这有助于在处理数据冲突时降低复杂度,封装结果。
- 有很多冲突,例如lb和bne的冒险,结构冒险,控制冒险等。解决方法就是AT法判断阻塞+无脑转发。相关测试样例在测试方案中包含了。
- 我是手动构造的样例。首先测试指令的基本功能,如果该指令是有符号数,那么还要测试负数的情况。之后再考虑转发和阻塞,如果该指令很早就要用到操作数(例如bne),那么就在让上一条指令写入该指令需要用的寄存器,测试阻塞功能。同时也要测试该条指令能否正常转发,因此如果该指令写入某一寄存器,那么下一条指令就要对该寄存器进行操作,验证是否转发成功。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2025-07-01
CPU_P4_design
1....

2025-06-30
CPU_P3_design
1....

2025-07-01
CPU_P5_design
1....

2025-07-01
CPU_P7_design
1. 分析指令集 经过分类,指令共包含R型指令和I型指令 列出其对应的32位机器码,寻找共性差异 R型指令: Type Op Rs Rt Rd Shamt Func 解释 add 000000 (5) (5) (5) 00000 100000 相加(rs+rt->rd) sub 000000 (5) (5) (5) 00000 100010 相减(rs-rt->rd) and 000000 (5) (5) (5) 00000 100100 rs & rt -> rd or 000000 (5) (5) (5) 00000 100101 rs | rt -> rd slt 000000 (5) (5) (5) 00000 101010 rs < rt ? 1 : 0(signed) sltu 000000 (5) (5) (5) 00000 101011 rs < rt ? 1 : 0(unsigned) mfhi 000000 00000 00000 (5) 00000 010000 HI...

