
OS_lab2_实验报告
1. 思考题
在编写的 C 程序中,指针变量中存储的地址被视为虚拟地址,MIPS 汇编程序中 lw 和 sw 指令使用的地址也被视为虚拟地址。CPU访问的都是虚拟地址,通过MMU来转换成对应的物理地址,最后访问内存中的数据。
首先,用宏来处理链表可以化简链表的操作,通过将特定功能的代码封装在宏定义中,可以在实现特定功能时简化操作,增加代码可读性和可维护性。其次,当链表的操作需要修改时,由于该操作会被大量复用,如果逐一修改工作量太大,而用宏则可以只修改宏定义,方便更改。最后,很多种类的链表都包含相似的操作,只要这些链表结构相同,就都可以用这些宏定义来实现相似的操作,只是传入的参数不同,方便了众多链表的使用。
在实验环境中,有单向链表、双向链表、单向队列、双向队列、循环队列。 单向链表插入只需前者指向新者,新者指向后者即可。双向链表插入操作需要新的节点指向前后节点,前后节点再指向新的节点,需要额外判断是否next指向了NULL。循环链表与双向链表运行代码量基本相等,需额外判断是否next指向了头指针。特别的是,插入到头结点对三种链表而言性能相似,单向链表与双向链表插入到尾结点均要遍历完整个链表。 单向链表的删除操作复杂度为O(n),因为需要靠循环才能找到上一个链表节点的位置,双向链表及循环链表的删除操作与插入性能相近,也还是需要额外判断NULL或HEAD。删除头结点对三种链表而言性能相似,而单向链表与双向链表删除尾结点还是要遍历。
结构如下:
1 | struct Page { |
答案选C。Page_list中含有的是Page结构体指针头。每一个Page内存控制块都有一个pp_ref用于表示其引用次数(为0时便可remove),还有一个结构体用于存放实现双向链表的指针。
ASID的必要性: 同一虚拟地址在不同地址空间中通常映射到不同物理地址,ASID可以判断是在哪个地址空间。例如有多个进程都用到了这个虚拟地址,但若该虚拟地址对应的数据不是共享的,则基本可以表明指向的是不同物理地址,这也是一种对地址空间的保护。
可容纳不同地址空间的最大数量: 64个,参考原文如下: Instead, the OS assigns a 6-bit unique code to each task’s distinct address space. Since the ASID is only 6 bits long, OS software does have to lend a hand if there are ever more than 64 address spaces in concurrent use; but it probably won’t happen too often.
tlb_invalidate 中 调用了 tlb_out。
tlb_invalidate 的作用是:找到tlb中对需要清除的虚拟地址对应的页表项,并将其全部清零。
1 | LEAF(tlb_out) |
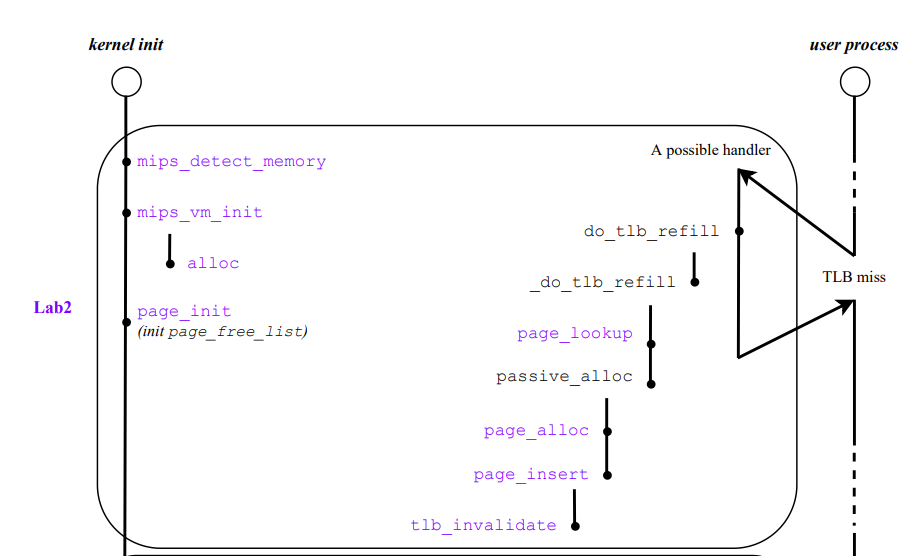
CPU一开始先探测可用的物理内存,数据由QEMU给出,之后根据页面大小计算出物理页框数量。然后根据对应数量alloc出来相同数量的页控制块,之后将已经被kseg0中代码占据的页控制块标记,将剩余的页控制块加入空闲页面队列。由于kseg0段的访存不需要用到tlb和页表,因此MMU仅通过映射的方式即可得到物理地址,然后将CPU初始化的代码存入物理内存中。之后空间页表队列建立好了,用户发出访存请求后,CPU就先访问tlb,如果找到物理地址则直接访问。若没有找到则进行缺页中断,进行tlb重填,其中就会用到我们写的函数和空间队列。
X86用到三个地址空间的概念:物理地址、线性地址和逻辑地址。而MIPS只有物理地址和虚拟地址两个概念。相对而言,段机制对大量应用程序分散地使用大内存的支持能力较弱。所以Intel公司又加入了页机制,每个页的大小是固定的(一般为4KB),也可完成对内存单元的安全保护,隔离,且可有效支持大量应用程序分散地使用大内存的情况。
x86体系中,TLB表项更新能够由硬件自己主动发起,也能够有软件主动更新。分段机制和分页机制都启动:逻辑地址—>段机制处理—>线性地址—>页机制处理—>物理地址。RISC-V提供三种权限模式(MSU),而MIPS只提供内核态和用户态两种权限状态。
RISC-V SV39支持39位虚拟内存空间,每一页占用4KB,使用三级页表访存。页表基地址(page table) 为PTbase。
页中间目录基地址(page middle directory) PMDbase:
(PTbase << 12) >> 3 + PTbase
页全局目录(page global directory) PGDbase:
(PTbase << 21) >> 3 + PMDbase(三级页表页目录的基地址)
页全局目录项(page global directory entry)PGDE:
(PTbase << 30) >> 3 + PGDbase(映射到页目录自身的页目录项)
2. 难点分析
理解CPU访问的都是虚拟地址,而虚拟地址到底是哪个实际的物理地址,这个是由MMU来决定的。在MIPS框架中,有四块内存区域,分别是kseg0,kseg1,kseg2,kuseg。其中前两个通过高位置零的操作就可以映射到物理地址中,不需要借助tlb,因此想要访问某一个具体的物理地址,可以直接通过kseg0段的虚拟地址来访问。
kseg0段一开始存储了操作系统内核的代码,以及页控制块等,这些代码已经存储到了对应的物理内存中,剩余可用的物理内存组成空闲页控制块,用来分配给kuseg。
链表的宏定义。链表的结构是,有一个指针结构体和一个被引用次数。其中指针结构体有指向下一个链表节点的指针,和指向前一个链表中指向下一个节点指针的指针。通过这样的设计,可以很轻易地修改链表,方便插入和删除操作。
页表分析。页表定义了很多的函数。page_walk函数的作用是,在二级页表结构中查找返回虚拟地址的页表项指针。如果二级页表缺页,会尝试创建一个。page_lookup函数既可以返回在二级页表结构中查找返回虚拟地址的页表项指针,同时也可以返回物理地址所对应的页控制块。page_insert函数可以建立虚拟地址和页控制块的联系。page_remove可以清除虚拟地址和页控制块的关联。page_decref可以减少页控制块被引用次数,如果减少到0则调用page_free将该页框加入空闲页表队列。
宏定义分析。

tlb_invalidate的作用是删除虚拟地址和物理地址在tlb中的对应关系,其中调用了tlb_out。如果CPU访问失败,则会触发缺页中断,调用do_tlb_refill函数,该函数会先为虚拟地址分配一个物理页框,然后填写到tlb中。
3. 实验体会
链表的宏定义需要熟练掌握应用,今后还有很多能用到的机会。同时自己实现的宏定义也要好好检查,否则课下的问题有可能会引发课上的错误。
虚拟地址和物理地址和页控制块的转换宏定义也需要熟练掌握,熟练掌握这些宏定义可以让我们快速完成想要的操作,更加方便简洁。
要好好理解多级页表的访存机制,十分清楚,这样才能在底层去操作。
4. 原创声明
本实验报告大部分原创,少部分参考了北航操作系统课程lab2实验报告 - 南风北辰 - 博客园 (cnblogs.com)该博客。全部内容都带有自己的思考。




